
线段树
线段树:线段树是一种二叉树数据结构。其每个节点代表一个区间,根节点代表整个区间,叶子节点代表最小子区间,是平衡二叉树,高度为$(O(log n))$。它能高效进行区间查询、单点修改和区间修改等操作,操作时间复杂度一般为$ (O(log n))$,常用于数组统计、区间更新与查询等场景,可提高相关算法的时间和空间复杂度。
建树(分治思想)
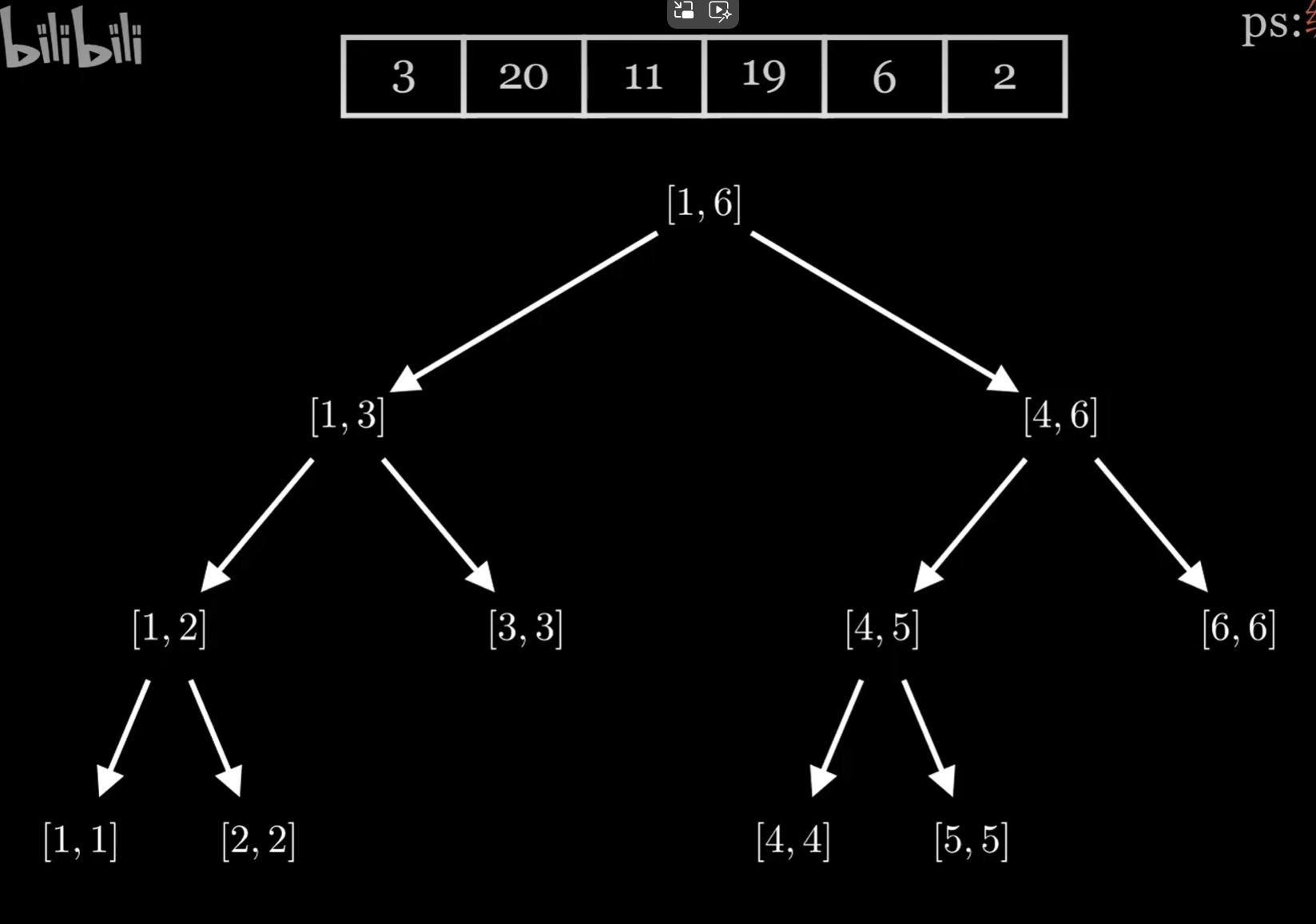
通过观察,发现我们如果为每个节点补足NULL,它形成了一个完全二叉树,于是我们有以下的规律:
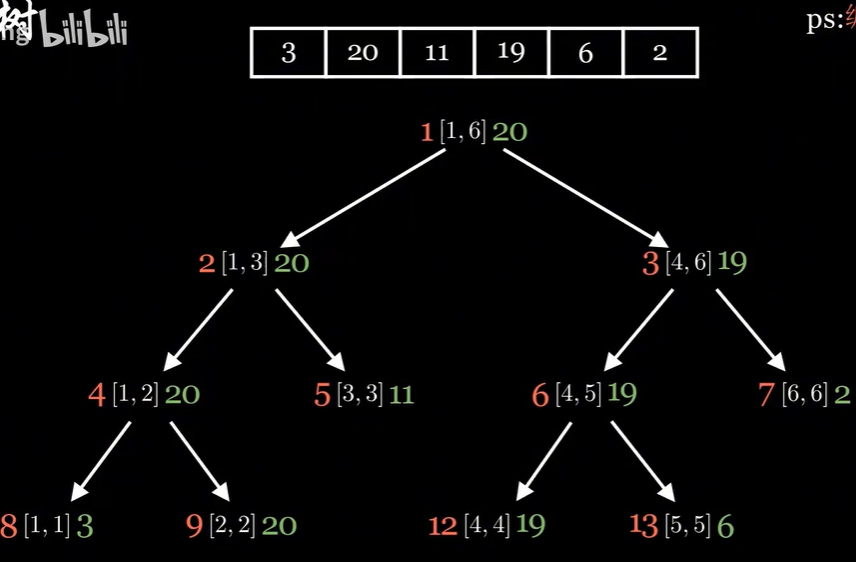
$$ parent_i = \left\lfloor \frac{i}{2} \right\rfloor $$$$ left_i = 2 * i , right_i = 2 * i + 1 $$每个节点存储下各自对应区间的最大值,于是我们得到:
区间查询
假设我们要查找区间$ [2,3] $的最大值,我们先看到root节点,发现$[2,3]$与$[1,6]$并不完全匹配,所以我们继续向下遍历,当到达节点4的时候,发现$[2,3]$与其左右孩子均有交集,于是我们兵分两路,分别以此类推的去找$[2,2]$和$[3,3]$的最大值。
最后找到5和9节点,答案就为$max(tree[5],tree[9])$
单点更新
假设我们尝试把原数组的第二个数字更新为6,我们一样按照区间查询的思想找到$[2,2]$这个节点,并依次向上更新整个线段树。
区间更新
定义:为一个区间内的所有值加上一个常数。
为了使得时间复杂度保持在$O(logn)$,于是我们引入一个新的概念——懒标记,由于最初没有任何区间更新,于是我们初始化所有懒标记为0。
我们尝试令区间$[4,6]$的每个元素+1,还是按照区间查询的思想找到符合的节点,这里我们找到节点3,发现它与我们要更新的节点完全匹配,于是我们把节点3的值加上1,为了优化性能,我们在这里偷个懒——把更新请求存储到节点3的lazy标记上,如下图所示:

所以懒标记的作用就是允许我们延迟更新操作,只在有需求的时才真正执行。
最后别忘了依次向上更新数组。
我们再来假设给$[4,5]$的每个元素+1,依旧先找到匹配的节点。
当到达节点3的时候,我们发现区间并不完全匹配,于是在继续向下更新时,我们要先检查节点3的lazy标记,由于其不为0,说明之前有偷懒未执行的更新操作,所以此时要对lazy标记进行“下发”处理:将其标记的值1传递给其左右孩子节点6和7,更新6,7的值和懒标记,同时归零节点3的懒标记,如下图所示:

接着遍历,我们来到节点6,发现此时节点6与查询区间$[4,5]$完全匹配,于是我们更新节点6的值,并且在节点6的懒标记上加上我们的更新请求,如图所示:

最后还是别忘了依次向上更新数组。
懒标记对区间查询和单点更新的影响
由于懒标记的特性,所以在进行区间查询或单点更新的时候,如果遇到某个节点有懒标记,我们必须先对lazy标记进行“下发”处理,然后再继续查询。
当然,单点更新还是别忘了依次向上更新数组。
代码实现
我们先定义一个node节点:
|
|
接下来我们实现了线段树的构建函数build:
|
|
对于懒标记的处理pushDown:
|
|
查询函数query:
|
|
单点更新函数update:
|
|
区间更新函数updateRange:
|
|
最后强调:为了避免越界问题,线段树的大小通常会初始化为原始区间大小的4倍
class模板
|
|